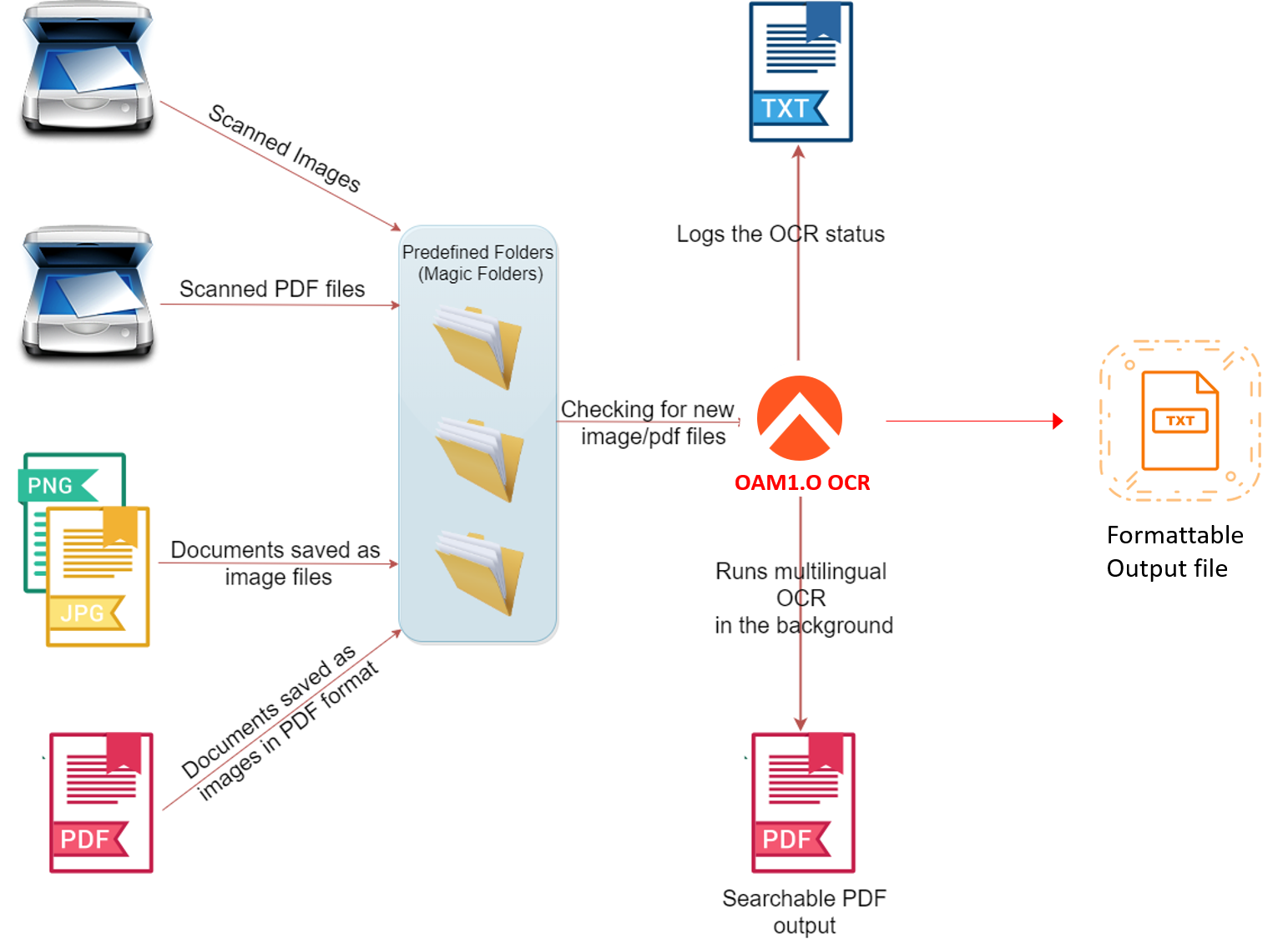
Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image.
“ Imagine you’ve got a paper document - for example, magazine article, brochure, or PDF contract your partner sent to you by email. Obviously, a scanner is not enough to make this information available for editing, say in Microsoft Word. This needs an OCR software that would single out letters on the image, put them into words and then - words into sentences, thus enabling you to access and edit the content of the original document.”
OCR is a combination of multiple technologies:
Image processing and cleanup. This involves auto contrast, cleaning up small dirt pixel in the white background (noise reduction, despeckle), black border removal, adaptive thresholding, and so on. If you just do a naive threshold, you may get a bunch of alternating pixels (noise), but intelligent threshold keeps connected gray pixels connected in the black and white output. You need adaptive threshold to deal with unevenly lit background, where the threshold level is calculated for each pixel after doing some convolution. Perhaps even lens correction and shake reduction, as these days the input of coming from smart phone rather than desktop scanners.
Straightening of the image (deskew). Characters should follow a straight line, and if they don’t, the dominant angle needs to be detected, and the paper de-rotated. Optionally, if you have a black border, that may also be used for angle detection. When the input is from a smart phone, you may actually need to stretch the four corners as well.
Segmentation: Separating text from lineart from halftone bitmap regions, which requires a neural network on its own. Finding blocks of text-like structure, paragraphs, lines, characters. Character recognition itself only works with a row of text at a time, not a full page.
OCR also involves writing out PDF, HTML, or a Word document. Often there’s a GUI for manual error correction, in case a word was unreadable, and its meaning couldn’t be guessed.
Can see how it’s a combination of multiple fields of expertise, from image processing, similarity matching, neural networks and NLP. Many lifetimes of engineering, with each iteration the accuracy improving gradually. Overall, it’s an unsolved problem, as we’re nowhere near human level of intelligence.
The more domain-specific can be the better accuracy achieved. In form recognition, know what each form field may or may not contain (numbers, names, cities, etc.). For example, the post office uses the postal / ZIP code as an error correction code for the city and state. Now that we’ve perfected handwriting recognition, we no longer write anything by hand. A century ago, mail was sorted by hand while being transported by train. By the time we figure out how to OCR books, books only exist in electronic form. By the time we figure out how to machine-read a tax form, everyone is doing their taxes electronically.